Congestion Control Triggers
We have discussed congestion control basics in a previous article. In this article we will focus on the starting point of congestion control action, i.e. generation of congestion control triggers. Congestion Control triggers are generated when the system senses that some resource is getting overloaded. The congestion trigger reporting software then senses the magnitude of overload and reports it to the congestion control software.
Here we will cover various mechanisms of congestion control trigger reporting. The following types of congestion triggers are covered:
- CPU Occupancy Triggers
- Link Utilization Triggers
- Queue Length Triggers
- Protocol Congestion Triggers
- Resource Occupancy Triggers
CPU Occupancy Triggers
Most Realtime systems should be designed to operate with average CPU occupancy of below 40%. This leaves room for addition of more features that might require more CPU time than the current software. This also leaves headroom for sudden increase in CPU requirement due to fault handling and maintenance actions.
Increase in CPU utilization is a very strong indicator of increasing load on the system. Systems should be designed to report congestion triggers when CPU utilization over a few minute interval exceeds 60 to 70%. The CPU overload abatement trigger should be reported when the CPU utilization falls below 50%.
As you can see we need to have a good mechanism for measuring CPU utilization. Unfortunately, measuring CPU utilization can only be approximate. We discuss two algorithms commonly used for CPU utilization measurement:
- CPU Occupancy Sampling
- Lowest Priority Task Scheduling
CPU Occupancy Sampling
This technique uses the periodic timer interrupt to obtain an estimate of CPU utilization. Typically the timer interrupt is executed with a 10 ms periodicity. Whenever the interrupt is scheduled, it increments a "CPU active" counter whenever it finds that a task is active at that instant. A "CPU inactive" counter is incremented when no task is found to be active at that time. An estimate of CPU occupancy can be obtained by using the values of these counters.
This technique only gives a very rough estimate of the CPU utilization. For most systems this technique suffices. However, the biggest drawback of this algorithm is that it does not work when some task is being scheduled periodically.
Lowest Priority Task Scheduling
This technique works by designing a task that is supposed to run at the lowest possible priority in the system. This tasks is designed to be always ready to run. Since all useful application tasks have a priority higher than this task, the operating system will schedule this task only when it finds that no other task is in active state. A good estimate of CPU utilization can be obtained by keeping track of the time between successive scheduling of this task,
In most cases this technique works better than the sampling based technique. However this algorithm does not take into account the CPU time spent in interrupt handling. Thus adjustment factors need to be applied if a system spends a lot of time executing interrupt service routines.
Link Utilization Triggers
Link Utilization needs to be carefully monitored when the link bandwidth is limited. If the utilization of links exceeds a 50-60%, a link congestion trigger should be reported. Link congestion abatement condition should be reported when link congestion goes below 30-40%.
Link utilization can be calculated by keeping track of number of bytes of data transmitted in a given period. Dividing this number by the maximum number of bytes that could have been transmitted gives an idea of link occupancy. For example, consider a link with a capacity of 80 Kbps (i.e. 10 K Bytes per second). If during a 10 second interval 25 KB data is transmitted, this represents 25% link occupancy as a total of 100 KB data can be transmitted if this link is fully loaded.
Queue Length Triggers
When a system encounters congestion for a particular resource, the queues for the entities waiting for the resource will increase in length as more and more entities have to wait for service of the resource. This applies universally to all types of resources. For example, consider the following queuing scenarios:
- When the link occupancy is high, transmit protocol queues will be backlogged.
- When the CPU occupancy is very high, the ready to run queue maintained by the operating system will increase in length.
- Also high CPU occupancy can lead to backlogging of receive protocol queues if the task involved in protocol processing is not getting scheduled.
Backlogged queues lead to delays. Queuing Theory provides a very simple equation describing the relationship between resource occupancy and the delay involved in obtaining that resource.
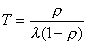
Here T is the average delay for the resource, the arrival rate is given by lambda and and occupancy is given by p. As occupancy approaches 1 (i.e. 100%), the denominator approaches 0, thus the total delay experienced will race towards infinity.
The above equation underscores the importance of generating congestion control triggers in time. Whenever the queue length exceeds a threshold, a congestion trigger should be immediately generated. This will give the congestion control software sometime to initiate action and bring the resource occupancy down. If the congestion trigger is delayed, the system might reach pretty close to 100 % resource occupancy, thus leading to terrible service to all users of the system.
Protocol Congestion Triggers
Many protocols like SS7 have inbuilt support for congestion control. Whenever a congestion condition is detected, these protocols generate a congestion indication. This indication can be passed to congestion control software for further action. Protocol congestion triggers can help in detecting end-to-end congestion in the system.

When a protocol congestion condition is detected, congestion control software will have to further isolate the exact cause of congestion. Sometimes the congestion control software will have to work in tandem with the fault handling software to isolate the real cause of congestion. (Keep in mind that a link with high bit error rate will also lead to protocol congestion) Consider a case where node A and C are communicating via a node B. If the protocol handler at A generates a protocol congestion trigger towards C, the congestion could be present at any of the following places:
- Node A CPU is overloaded and is not processing packets received from Node B.
- Link between Node A and Node B is congested.
- Node B CPU is overloaded and it is delaying routing of packets between A and C.
- Link between Node B and C is congested.
- Node C CPU is overloaded and is not processing packets from Node B.
You can see from the above description that isolating the protocol congestion trigger can be daunting task even in a simple network shown above. Imagine the complexity of isolating congestion source in a big network with hundreds of nodes.
Buffer Occupancy Triggers
Just like any other resource, a heavily loaded system may run out of buffer space. This can happen due to memory leaks in the software. In a stable system, buffer congestion might be reported when it faces congestion. This happens because a large number of buffers are queued up waiting for resources.
Just like all other congestion triggers, an onset and abatement level is defined for buffer congestion. When the number of free buffers depletes below a certain threshold a congestion trigger is reported to the congestion control handler.
Resource Occupancy Triggers
We have covered basic computing resources like CPU, link bandwidth and memory buffers. Most embedded and real-time systems deal will other resources like timeslots, DSP processors, terminals, frequencies etc. Congestion triggers might be generated when the system is running short on any of these resources.